
Securing Critical Components of Cyberphysical Systems
Bridging foundational capability gaps to spur an AI resilience renaissance, a follow-up



Read part one of this series here:

You can think of any cyber-physical system as consisting of
the hardware that is running the computation or infrastructure,
the software that is controlling the hardware, and
the people who are running, operating, or communicating with the software.
For the system to work well, you need all of these components to work flawlessly, as compromising any single component can often compromise the entire system.
But things rarely work flawlessly in the real world. Software has bugs, leading it to do things that the system operators don’t intend it to do. Some of these are critical vulnerabilities that can be exploited by attackers. Hardware might have accidental and intended vulnerabilities. It can be hard, expensive, or illegal to pop the hood on commercial hardware and software systems to examine their inner mechanics. And sometimes people try to get the system to do the wrong thing, or people try to gain unauthorized access to the system.
Unsurprisingly, if a cyberattacker wants to compromise a cyber-physical system and can deploy powerful AI systems, then each of these vulnerabilities become easier to exploit. However, a defender could also leverage a powerful AI system themselves. The remainder of this post will discuss specific projects that would enable defenders to better leverage AI systems.
To structure these potential projects, we’ve developed a tiling tree structure, which intends to be mutually exclusive and completely exhaustive, by asking questions that each have a small number of possible answers.
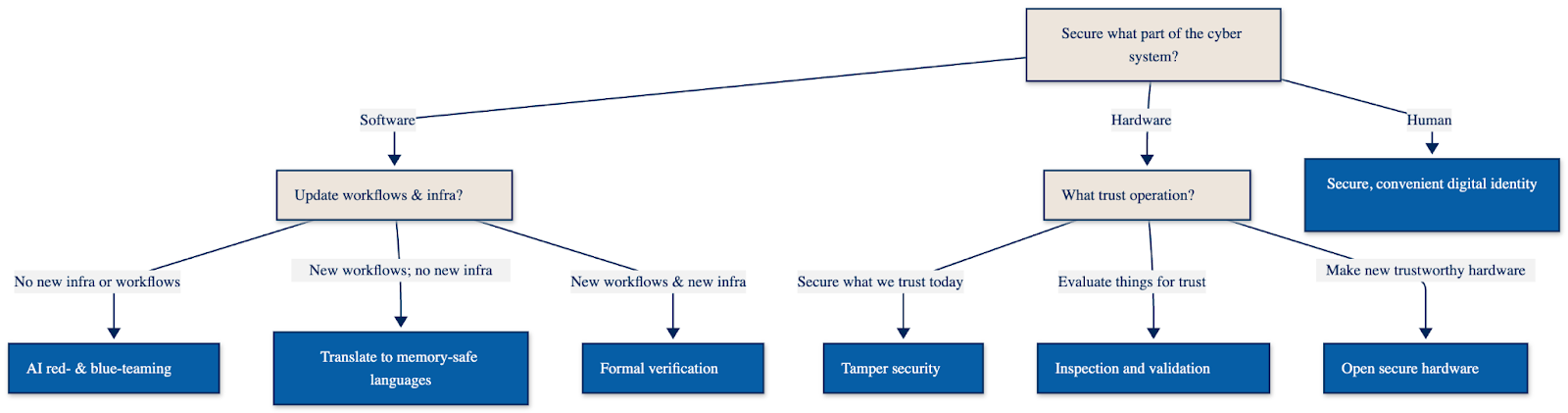
The first question is “What part of the system are we trying to secure?”
There are three choices here: software, hardware, and the people. Let’s take each in turn:
Securing Software
The world of software moves very quickly, so the deciding factor for what kind of technology you need to secure your deployed codebase is likely your answer to the question of “how fast do you want to - and how fast can you - deploy changes to your software?” Some software is in continuous deployment, some can only be updated with physical contact, and other software require intermediaries to help deploy it. Think about the difference between a webpage hosted on your home server, an iPhone app, and the control software on a nuclear submarine.
To radically improve software security with near-term AI capabilities, we can then ask if we’re willing to build new security infrastructure and/or force operators of various cyberphysical systems to change their workflows. This infrastructure is composed of tools, libraries, definitions, and datasets that enable humans to reason about wholly novel workflows. Creating this infrastructure takes time and human effort because much of it is sourcing tacit knowledge and building consensus around definitions. Doing this work takes time and attention, which will only become more costly as the pace of technological development accelerates.
If groups are not interested in using new tools or changing their workflows yet want better security now, the best we can do is to provide operators of critical cyberphysical systems with AI-based red teaming and blue teaming beyond their human security experts, like the kind Evan wrote about in “Preventing AI Sleeper Agents”.
Red- and blue-teaming is a standard practice in which a so-called “red-team” simulates attacks, and works to discover vulnerabilities, while the blue team defends, and both teams afterward collaboratively improve the system security.
These security audit workflows already exist in software engineering efforts and AI systems have already been shown to be quite effective at identifying and fixing various types of vulnerabilities. The leading AI labs each have an effort to build AI agents to perform this work. And a number of startups and longstanding companies have begun to offer this as a service.
However, leaning into this AI-based red-and-blue-teaming approach wholesale risks triggering an arms race, since the attacker only has to find one vulnerability, but the defender has to fix every bug in every system. Because this effort requires creating AI agents that are very good at finding vulnerabilities, it produces useful tools and compelling targets for bad actors as well as good ones. Because these AI tools can be weaponized, they’re (understandably) generally not accessible to the public, which adds a major operational barrier to broad adoption as well.
–
If operators are willing to use new workflows, but they do not have time to build significant security infrastructure, then we should use AI to drive adoption of existing memory safety technologies.
Most computer programs rely on accessing a region of computer memory on the system in which they are running. If a computer program reads or writes to memory outside a narrow scope allocated to it, this can lead to the program behaving unpredictably, crashing the computer, or modifying the system’s behavior in catastrophic ways. This problem is exacerbated by the incredible complexity in the abstractions with which memory is treated at a hardware level, in how complex computations are executed in hardware, and how different operating systems manage different programs. These kinds of memory handling errors have been reported to account for roughly 70% of exploitable vulnerabilities from Google and Microsoft.
This problem is fixable. For instance, the Rust programming language has been engineered to rule out memory errors. Sadly, most software is not written in Rust, but it is increasingly possible to make the translation from other languages into Rust, with the help of AI.
Happily, there has been movement on the federal level on this topic, and support for continued movement is bipartisan. In 2024, the Office of the National Cyber Director released a report which the White House announced with a press release titled “Future Software Should Be Memory Safe.” In June 2025, CISA and NSA issued a joint guide explicitly advancing adoption of memory-safe languages, citing the 2024 ONCD report. Likewise, DARPA has a program focused on building tools to Translate All C To Rust (TRACTOR), and there’s an FRO proposal (also part of that IFP Launch Sequence collection) to dramatically scale this effort.
One limitation of this memory safety approach, however, is that it does little to mitigate the other ~30% of security vulnerabilities. In addition, many operators of critical infrastructure like electrical grids currently seem unlikely to accept and run AI-generated translations of their software into a new language with which they have no expertise. Of course, this may change over time, but it poses a meaningful barrier to adoption currently.
–
If someone is willing to invest in both new security infrastructure and new workflows, they should build and deploy formal verification as the default for software.
Formal verification brings together three critical components:
The code that runs the program
A specification of what that software should do
A mathematical proof that shows that the code satisfies the specification
Formal verification provides the strongest security by mathematically proving specific security properties in a way that guarantees they will hold against any and every adversary, even an advanced AI. It makes code provably secure. This is a powerful approach that depends on cutting edge research, and we can immediately identify several projects that would meaningfully derisk and accelerate it.
Automating the first and third items, i.e., generating the software and constructing the proof, are already being accelerated by AI. The former have been demonstrated by Cursor and Claude Code, while the later has been demonstrated in pure math with recent projects like AlphaProof and Aristotle that leverage Lean. But more progress is needed before this can meaningfully improve cybersecurity.
For one, we should make more evals, benchmarks, and RL environments for common formal verification tasks. Several leaps in large language model capabilities have been accelerated by the creation of evals and benchmarks which can guide progress in the model’s capability at a particular genre of task, and the development of RL environments in which a model can self-train in a reliable way without needing a great deal of additional data. This should include making models better at using formal verification languages and tools (like Lean or Rocq), fixing proofs with mistakes, or identifying gaps in specifications. The same scaffolding could help us develop even more powerful automated formal verification models.
Another project – which we are aiming to incubate as a FRO – would involve building a set of AI based tools to help humans generate and validate formal specifications. Humans - or at least most humans - don’t think or talk about their code in terms of set theoretic lemmas. But for something to be formally verified, even in Lean, it ultimately needs to devolve from the abstract and somewhat vague symbolic language we use when we speak or when we program software, to the language of formal mathematical proofs. Since the ground truth of “what should the program do” often only exists in the mind of the human operator or designer – and even then, may exist only in a fairly vague way - we need ways of helping humans convert their ideas about what software should ideally do into the exact language (Lean being an example) that a computer can prove theorems in. We believe this is complex, but ultimately quite doable given the current capabilities of LLMs.
One benefit to building formal verification infrastructure is that incremental adoption provides clear benefits. You might assume that replacing the software that runs existing critical infrastructure with secure alternatives must, at some point, involve taking away the old software and forcing operators to run new software they’ve never seen before. However, that isn’t true, because there are intermediary milestones leveraging formal specification and verification that are both helpful to operators and can increase trust.
An initial exploration for a particular system operator could involve using AI-based tools to generate a formal specification from their existing code, documentation, and user input. This specification can then be immediately useful for answering questions about the system, synchronizing code and documentation, and monitoring the active system without changing any operator behavior. This makes it easier for designers and users of engineered systems to understand aspects of system behavior, rather than having them simply replace their system with a version they’re told is secure.
Once the specification-based monitor is primarily finding bugs in the system, not bugs in the spec, the trusted specification can be used to filter anomalies, and eventually, AI systems should be able to generate verified code that is proven to have the security and functionality properties in the specification. This provides early value and fast derisking (especially compared to approaches like rewriting software in Rust), even for operators who run systems for critical infrastructure like electrical grids, regional utilities, and water plants.
Securing Hardware
We could also focus on hardening hardware systems.
Electronic hardware is essentially ubiquitous. A modern car contains thousands of different semiconductor chips. Now think about how many different chips there are in your house, from your internet router to your humidifier, baby monitor, and phone charger. Basically everything more complicated than a simple incandescent lamp has at least one.
Now, where were those chips made? Do you trust them not to do anything you don’t want them to do? Why? (Datacenters, hospitals, and power plants face a much harder version of these questions, yet may have no more dedicated resources than you do to answer them.)
Today, we typically treat hardware as a trusted, fungible commodity: as long as it runs the software we want, we don’t care what chip components power our cars and phones and home appliances. This may make it particularly unsettling for us when we learn that both software and hardware systems can induce nearly undetectable propagating vulnerabilities in cyber systems. As a result, if you want software to run reliably, you need to really trust your hardware as well.
For those of us looking to build resilience into our cyberphysical systems, the next question becomes whether we trust that our deployed hardware systems are secure, or we want to develop trust in it, or we want to build new systems from scratch so that we can trust them.
If we already trust our hardware, it stands to reason that we want to make sure we can continue to trust it in the future. That means protecting the hardware with tamper response measures, because hardware functionality can be compromised and (cryptographic) secrets can be extracted from devices if an attacker has physical access. If you want to make sure that attackers can’t steal an AI model, change your AI system, or read your private data, you need to make sure all the data is permanently erased if someone else gets ahold of it.
This technology could also be used to combat chip theft, export control violations, and other misuse, especially if combined with more destructive tamper response mechanisms and flexHEG monitoring and control capabilities.
The same tamper response hardware in a different form factor would also be useful for building sensors for situations in which you cannot afford for sensor data to be spoofed or fabricated, which could be useful for combating deep-fakes and disinformation. These sensors could make measurements or take images, and cryptographically sign that information with a private key; any tampering with the sensor would lead to the loss of that key, preventing adversaries from signing forged data on a sensor they’d compromised.
–
Beyond finding ways to perpetuate existing trust into the future, you can also build trust in existing deployed hardware that you can’t currently vouch for.
Fighting forged and knockoff chips - hardware that claims to be of a certain provenance but is actually a fake - is already a challenge today, and while defense capabilities here will likely grow faster than offense, the stakes of making a mistake will definitely rise, as cyberphysical systems become increasingly critical to the function of society.
There are demonstrations today that show how people can use infrared light to compare suspect chips to a reference and thereby identify chip forgeries. These demonstrations, however, only catch glaring differences between chips, wherein the two chips sit inside identical centipede-like black enclosures and have meaningfully different functionalities. A more ambitious version of chip validation would not simply compare a chip at a high level to a reference, but provide detailed analysis of the chip’s functionality. This is a much harder (and currently virtually intractable) problem, but it is theoretically possible and could be unlocked with AI capabilities. Additionally, this project has a compelling synergy with an earlier project on our list: you should be able to leverage gains in formal specification capabilities to help do the latter verification of a suspect chip and its functionality.
–
Lastly, if for whatever reason you can’t afford to build trust in existing hardware because you believe it to be too thoroughly compromised or just can’t take the risk that it is, then building de-novo hardware transparently may be the best option to achieve trustworthy security.
One option could be to re-develop high transparency and reliable supply chains, starting with relevant raw minerals, the processing of silicon into ingots, and running semiconductor manufacturing in a highly transparent, secure, and monitored way.
Another option would be to choose specific, high-impact chips (for instance, those monitoring AI usage), and design freely available and open, secure versions of those chips. This would enable anyone to trust-but-verify, providing the same level of security expectations that we have for the most trusted open source libraries. If competitors can all build trust in the same hardware for critical applications like AI governance (e.g., flexible hardware-enabled guarantees, flexHEG), these devices could enable new forms of corporate agreements, international treaties, and user rights/privacy.
Another factor in hardware resilience would be deploying back-up or duplicate systems. For instance, for electricity supplies, this could look like stockpiling transformers (which are notoriously expensive and have long lead times) or decentralizing the electrical grid by facilitating progress on microgrids, battery back-ups, geothermal, and small modular reactors.
Securing the Human Factor
If the hardware and software are both secure, then we still need to consider the human accessing and operating the system.
Humans provide a number of inputs to cyberphysical systems, from authentication information like protected passwords or other evidence of identity, to decision inputs that drive those systems into new states in the real world. While preventing humans from ever making a mistake would require dystopian overreach, new technology could increase our confidence that (a) the only agents with access to a system are humans who are supposed to have it and (b) those humans aren’t accidentally taking actions that are obviously inconsistent with their goals.
To protect against unauthorized access, we could build and deploy radically better identification systems by replicating the internet’s Domain Name Service (DNS) workflow, which gives your computer cryptographic assurances that you’re connecting to the website and server your expect, whether you’re looking for convergentresearch.org or google.com. There are relevant proofs-of-concept like Worldcoin, which provides robust biometric identification, and the Estonian e-ID, which demonstrates that citizens can benefit from government-issued cryptographic identities. In maturity, this system could apply the gold standard of security, which involves combining something you are (biometric), something you have (ie. a hardware key like an HSM, or hardware security module), and something you know (password) into a robust access request.
To protect against outcomes where the right person makes the wrong choice when they interact with a cyberphysical system, there might be reasonable low-hanging fruit in detecting and preventing errors. It might be finally possible for us to introduce privacy-preserving AI assistants that help people making critical decisions to receive relevant, timely input of additional information. This could look like a worker’s AI-powered safety goggles alerting them that in the course of a routine inspection they just set the dial to 1101, which they have never done before and which could lead to the system departing from nominal behavior, and perhaps they meant 1011 instead. You can imagine deploying unblinking, unfaltering AI assistants at work across areas like transit, facility monitoring, and medicine, radically increasing the awareness and knowledge of drivers, monitors, and doctors, but without taking the humans out of the loop. It’s worth noting generally, but especially for applications like this, that the trustworthiness of the AI system as well as the full AI stack become critical, especially as humans increasingly rely on AI assistance.
Lastly, there is a question of recovery after failure. If we’re truly preparing to become resilient against even the worst cybersecurity scenarios, it’s important to acknowledge that failures might still happen even after all the precautions above are taken, and so it’s worth investing in making those failures less bad if they do happen. For a tiny fraction of the US defense budget, we can ensure that America retains the ability to rapidly rebuild critical infrastructure using basic tools and domestic materials. In a world where supply chains can vanish overnight, this capability may determine national survival. We ought to establish a robust baseline repository of tools and knowledge across the US that would enable a cold-start of technology supply chains in the event of catastrophe, rapidly bringing America back to the level of technological capabilities it had in the mid 20th century.
If you would like to see these ideas and more in table format, check out our Google Sheet here. We also have notes for interested funders with potential performers and estimated budgets; please reach out if you’re interested!
 | A guest post by
|
We need more articles on security and cyber security. It seems to not matter to many until it does